Working in a Worldwide Invisible College: the Internet and the Global Scholar

HTML version of paper originally presented at CAUSE '94, Melbourne, July, 1994. (c) Andrew Treloar, 1994. Last revised June 5, 1996.
Abstract
This paper will discuss the ways in which the Internet and related technologies can enhance and alter the activities of those in the scholarly community. A range of Internet services facilitating computer-mediated communication and retrieval of networked information will be discussed, as well as their implications for the way academics work. The paper argues that a range of tools and technologies available through the Internet provide scholars with new ways to form their own 'invisible colleges', influence how they do their research, and provide them with new ways to teach.
Table of Contents
- Introduction
- The Business of a Scholar
- Internet Tools and Services
- The Global Scholar's Workbench
- Conclusion
- References
Introduction
This paper will attempt to explore some of the ways in which the Internet can change the way in which academics operate.
The first section will focus on what academics have traditionally done and how. The emphasis will be on defining some of the core activities associated with the scholarly life. Traditionally in this context should be taken to include current practices that have not changed substantially from the past.
The next section will look at the phenomenon called the Internet and what it makes possible, for scholars and other users. Here, the focus will be not on the details of the technology but on the types of information services and tools that are currently available.
The last section will address how this can and will change what scholars do. The scholarly activities of the first section will be overlaid on the technological capabilities of the second, revealing a range of exciting possibilities and actualities. The focus will be particularly on the development of global 'invisible colleges', and new ways of teaching and performing research.
The Business of a Scholar
"Scholar. 1. One who is taught in school; ... 3. A learned or erudite person;
Scholarship. 1. The attainments of a scholar; learning, erudition;" Shorter Oxford English Dictionary, Third Edition.
"To talk in public, to think in solitude, to read and to hear, to inquire and to answer inquiries, that is the business of a scholar" Samuel Johnson.
The dimensions of what scholars do are represented in large part in the quotation from Samuel Johnson: talking, thinking, inquiring. They can be broadly summed up as research and teaching. Most modern universities add to these the dimensions of administration and community service. This paper will only address the research and teaching dimensions.
Research demands the gathering together and analysis of existing information from a variety of sources and the creation or synthesis of new information. It also requires a deep understanding of the scholar's chosen field. Traditionally, scholars have gained this deep understanding by first attending one or more institutes of education and learning through lectures, tutorials, workshops assigned readings and the like. They then remain current in their field through continuing to read the work of their peers (both formally and informally distributed) and through attendances at gatherings of other scholars such as conferences.
Teaching has traditionally been face to face, through a variety of structured educational experiences, including lectures, tutorials, workshops, as well as informal conversations. The increasing need for distance education has involved a replacement of lectures with other, often paper-based, materials, and interaction between teacher and learner via telephone.
The rise of information technology, particular networked computer technology, provides for completely new ways to do many of these activities, and improvements to existing ways. This paper will examine the Internet as an example, a pre-cursor of the sort of network that will become ubiquitous in the future.
Internet Tools and Services
The Phenomenon that is the Internet
In the last few years of this millennium, it has become clear that the world is seeing the emergence of a new way of working with information, based on computer networks and the services they provide. This new information domain is called variously cyberspace, the Matrix or simply the Net. It consists of networks interlinked on a global scale. These networks range from small scale Local Area Networks (LANs), city-wide Metropolitan Area Networks (MANs) through organisation-wide Wide Area Networks (WANs) to Global Area Networks (GANs). Some of the GANs, like Digital Equipment's DECNet, are proprietary to an organisation. Others like FIDONet are made up of numbers of small bulletin board systems (BBSs). Others again like BITNet are special purpose research networks. Lastly, there are the commercial GANs like Compuserve.
The Internet is a core part of this global network architecture - in a very real sense, the ultimate GAN. It can be considered as a 'network of networks', linking over 20,000 separate networks around the world and over 2 million host machines, many of these multi-user systems (Zakon [1994]). Most existing GANs and an increasing number of WANs have at least an email connection to the Internet; this enables at least 20 million users to communicate via email, with this number increasing by perhaps 2 million every month. Many of the more innovative and exciting information services that are being developed at the moment, such as Gopher and the World-Wide Web, are only accessible on the Internet proper.
At present, the Internet is going through a period of enormously rapid and exciting development. This makes it very difficult to predict how it might evolve. However, there are a number of general trends. Firstly, there is explosive growth in users connected, hosts providing information services, the range of information services available, and the tools to access these. New hosts, services and tools seem to appear almost weekly, making any figures out of date as soon as they are entered. Secondly, the Internet is increasingly driven by the spread of microcomputers and the Unix operating system. All of the new information access tools are based around the client-server architecture, running on multiple platforms and using standardised protocols. Thirdly, the user population is becoming more diverse as private service providers expand access to the Internet beyond the traditional academic and research base. Fourthly, there is a growing commercialisation of the Internet. The number of commercial networks connected is already more than half of the total. Private information providers are rushing to bring their services to the Internet community, often, but not always, for a fee.
Much of the excitement associated with the Internet is related to the information services available and the software tools used to interact with these. At the most general level, all such interactions with the Internet can be divided, after December [1994a, b], into Computer Mediated Communication (CMC) and Networked Information Retrieval (NIR).
Computer-Mediated Communication
Computer -Mediated Communication has a primary focus on communication between human beings, albeit supported by computer-computer communication along the way. It is likely that for most users, the CMC aspect of the Internet is their primary use, measured in terms of the number of hours they allocate to it. It includes such things as electronic mail, listservers, network newsgroups and multi-user dimensions (MUDs).
Email is probably the most used Internet service. It allows for rapid communication between users without the problems associated with 'telephone tag'. Email originally provided transmission of text messages only. The development of the Multipart Internet Mail Extensions (MIME) standard has enabled a range of other media types (graphics image, digitised movie, program file, etc.) to be attached to a normal email message. A number of gateways provide mail translation across the boundaries between the Internet and internal email systems.
Listservers provide for automated mailing lists. Typically users need to subscribe to a list via email before they can use it. From then on, any email message they send to the list is automatically copied to everyone else on the list. Such lists can be moderated (someone takes responsibility for vetting contributions and perhaps editing them) or unmoderated (no controls other than peer pressure apply). In excess of 5,000 specialised lists exist to facilitate communication on a bewildering array of topics. Some listserver software allows for automatic retrieval of information via email. The user sends a message requesting a certain file and it is returned by email.
Network newsgroups (also called UseNet News) are another way to enable shared discussions on specific topics. The main differences between news and listservers are that newsgroup traffic is automatically copied to sites that provide news access whether anyone is reading it or not, news disappears as it becomes stale, and that message traffic within newsgroups tends to be grouped into threads (or particular sub-topics of discussion). Newsgroups come into being, evolve and fade away on a time scale of years. Threads arise and disappear on a scale of days or weeks. Special newsreading programs are required to access news. There are upwards of 3,000 globally propagated newsgroups and many more that are specific to particular organisations.
Multi-User Dimensions (MUDs - originally standing for Multi-User Dungeons) initially evolved for the playing of fantasy-role games set in mythical/fantasy surroundings. They can best be described as text-based virtual reality environments. Users see a textual description of their location and interact with their environment and other users by typing commands. In a MUD, multiple users can simultaneously communicate, interact, and even create new parts of the shared reality. In many ways, a well-populated MUD can be viewed as a virtual community. A good example of such a community is LambdaMOO (MOO stands for MUD - Object Oriented), famous in Internet circles for the recent 'rape in cyberspace' case.
Networked Information Retrieval
The other major use of the Internet (everything other than CMC) can be loosely described as Networked Information Retrieval (NIR). Of course, when considering networked information, it should be remembered that other people on the Internet are equally valid sources. There is no inherent difference between querying a remote database of journal citations and sending email to a newsgroup asking for references. If anything, the interaction with other users through the newsgroup is likely to be more positive and elicit a wider range of more relevant responses! I have argued elsewhere (Treloar [1993]) that NIR tools and their associated services should be categorised according to the operations they support: retrieval, browsing or searching. This paper will group tools according to which of these operations is their primary focus.
Retrieval assumes the user knows what they want to retrieve and/or how to get there. Users locate the information they want by being told about it (electronically or in print form), by browsing information spaces, or by executing an electronic search.
The best-known retrieval tool is the File Transfer Protocol or ftp. Ftp allows the user to connect to a remote computer, navigate through a part of its directory hierarchy and copy files to a local computer. The user can either be known to the remote computer or unknown. In this case, they login with the id 'anonymous' and receive restricted access - hence the widely used term 'anonymous ftp'. Gopher, WWW and WAIS (see below) can also be used to retrieve information.
Browsing refers to the ability to navigate through an information space looking for items of interest. This is somewhat analogous to browsing along the shelves of a bookshelf or library. Browsing tools originally did not offer any search facilities, but this has now been added. These tools rely primarily on the underlying organisation of the information space to inform the user's movements. The pre-eminent browsing services available today are Gopher and the World Wide Web.
Gopher (Wiggins [1993]) is based around the familiar concept of hierarchies. A user accesses a remote Gopher server and is presented with a hierarchical menu of items and submenus much like a computer file system. The file system metaphor is a familiar one for organising documents, and Gopher generalises this to include documents of various types, a range of possible search options, telnet sessions to other computers, and gateways into other information systems.
In contrast to the hierarchical, menu-based, one hierarchy per server organisation of Gopher, the World-Wide Web (Berners-Lee [1992]), also written as WWW or W3, is a distributed networked hypermedia system. In practice what the user sees is a structured document with heading, sub-headings, highlighted links, and embedded graphics. Clicking on a link might jump to another part of the same document, display an image, play a sound file, show a movie or move to another structured document altogether. The location of these various resources is transparent to the user, and may be on their local machine, another machine in their building, or a machine on the other side of the world. Interest in WWW has increased dramatically since the release of the Mosaic WWW client last year. Mosaic supports numerous document types including various image formats, audio, and PostScript, and has gateways to Gopher, USENET News, FTP and WAIS. It can be used to provide the user with their own "customizable hypertext view of the networked universe" (Wiggins [1993], p. 46 - 47).
Searching involves asking a question and receiving an answer which may identify people, files, or servers. This answer may then lead to further searches, retrieval of items or browsing other parts of the Internet.
Tools for locating people (so-called Internet White Pages tools) include X.500, WHOIS, and Netfind. These are all ways of locating at least electronic mail information, and perhaps physical addresses, for Internet users. X.500 (CCITT/ISO [1988]) is an attempt to provide a hierarchically structured global directory service that has been under development for a number of years. WHOIS (Harrenstein, et. al. [1985]) relies on a less-structured database of registered network names that is local to an organisation. Netfind (Schwartz and Tsirigotis [1991]) tries to address the deficiencies of both X.500 and WHOIS by using a number of different heuristics to locate users. Starting with the users name and some approximate location information Netfind is surprisingly effective at tracking people down.
Tools for locating files include Archie and WAIS. Archie (Deutsch [1992]) provides a searchable database of files available from anonymous ftp sites worldwide. The databases are replicated around the world, and archie servers cooperate to keep them current. The Archie database is invaluable for locating particular files, if the name or part of it is known. WAIS (Kahle [1992], Stanton [1992] and Stein [1991]), standing for Wide Area Information Servers, is a distributed networked database system. WAIS supports keyword searches on text documents across one or more servers. The search results are given a relevance score out of 1,000; the higher the score, the closer the match to the search. Documents, once identified, can be retrieved. In excess of five hundred WAIS servers, most specialising in particular subject areas, are now available.
Server location tools include WAIS, Veronica, and a range of Web tools. In addition to querying databases of text, WAIS can be used to first search a database of servers looking for those dealing with a particular area before running a specific question against just those servers. Veronica (Wiggins [1993]) allegedly stands for Very Easy Rodent-Oriented Netwide Index to Computerised Archives, and can be used to search for particular words in the titles of gopher menus, thus facilitating the correct choice of gopher server. A number of prototype WWW indexing tools exist or are in development. At the recent 'Best of the Web '94' competition, the prize for the best navigational aid went to the World Wide Web Worm [WWWW 1994], an automatic title indexing service.
For a more detailed discussion of the range of NIR tools, refer to Foster [1993].
The Global Scholar's Workbench
The CMC and NIR tools and services discussed above have developed over time to meet the needs of a very diverse networking community. Not all of them were originally targeted at academics, but many in the scholarly community have shown a wonderful creativity in the way they have adapted and extended these tools to support things they have wanted to do.
As an example of this activity, consider the Centre for Networked Access to Scholarly Information (CNASI) run by Tony Barry at the Australian National University.

Figure 1 shows the Macintosh TurboGopher client accessing the CNASI Gopher.
CNASI provides a University focus based in the Library for the introduction of new techniques for the transmission of scholarly information utilising new technologies being developed in computing and networking. The Centre works in cooperation with any area of the ANU which wishes to develop new methods of information transmission to assist the scholarly endeavour. More information on CNASI activities can be found here.
This section will revisit the teaching and research dimensions of scholarship and concentrate in particular on ways the Internet can and is being used to support these activities. First though it is useful to look at ways in which the Internet can help scholars to work together more effectively. Such cooperation underlies both the teaching and research dimensions.
Invisible Virtual Colleges
One of the reasons that CMC tools on the Internet are so popular is that people love to communicate. In the academic community, the range of Internet tools makes it possible to make links with people one would never have met normally, and may never meet. In particular, it makes it possible to form invisible colleges of colleagues around the world. Such networks may be formal or informal and may use a range of techniques: private email lists, Listservers, newsgroups, MOOs and more. For an excellent discussion of the topic of networking over networks, consult Agre [1994b].
At the most informal level, a researcher might maintain a list of colleagues around the world who assist with their preparation of articles and conference papers. Early drafts can be circulated for comment, and pre-prints/reprints sent out once accepted. Of course, academics have been doing this sort of thing for centuries with print-based information. The difference here is the ease and speed with which it can occur. In fast-moving fields of research, waiting months or years for a paper to appear in a journal may involve an unacceptable delay. The ability to read and cite others work before it has been officially published or presented can be very valuable.
In a more formal way a listserver might be established to enable those interested in a particular topic to correspond. As an example, the National Scholarly Communications Forum was established in late 1993 to bring together parties interested in the effects of the networking revolution on Australian global communication and information access. Its founding members are the Australian Academies (Science, Humanities, Technological Sciences and Social Sciences), Australian Society of Authors, Australian Library and Information Association, Australian Council of Libraries and Information Services, Australian Book Publishers' Association, Council of Australian University Librarians, Committee of Australian University Directors of Information Technology, Copyright Agency Ltd., National Library of Australia, and Council of Australian State Libraries. To subscribe, send an email message to majordomo@adfa.oz.au with the message contents subscribe nsc-forum. Newsgroups can also be used to correspond with communities of shared interests, although the discussion is not always so focussed.
The facilities provided by MUDs are also starting to be used for serious scholarly discourse, enabling researchers to interact in a natural setting, and work cooperatively to solve problems or produce items of mutual interest. The ability to leave information in a virtual room for others to read when they visit is particularly helpful when cooperating across timezones. A number of examples can be mentioned. Researchers into Post Modern Culture can use the PMCMOO, and a MOO for the Institute for Advanced Technology in the Humanities (IATHMOO) is available at the same site. Biologists are able to hold meetings, discuss research, and critique papers in the BIOMOO. This also has a WWW homepage here. Researchers into Media and related areas can register for admission to the MediaMOO. This MOO provides a richly textured information space, drawing on the creative talents of a number of the MIT community. Members are encouraged to design their own virtual offices and link them in.
Teaching
A number of initiatives on the Internet are addressing ways of using Internet technologies to support the teaching process. Some of these are supports for conventional teaching while others are completely new. They can be considered under the headings of interaction with learners and delivery of educational content.
Interaction with learners
The most obvious use of the Internet in working with learners is the use of email. This can be employed to receive and answer questions, and to receive and return assignments. In dealing with questions, email is asynchronous and efficient. Asynchronous, because learners can safely leave messages if a staff member is unavailable, and receive an answer later. Efficient, because they can dial in from home and avoid making a possibly fruitless visit. I routinely inform my students that I process email messages before any other messages. When dealing with assignments, the mail package automatically time and datestamps submissions, and delivers them reliably. The assignment can then be corrected and annotated and mailed back. I currently use this method of submission in a unit on Electronic Information Sources and the Internet. The students have to learn to use email!
A number of universities have also employed newsgroups to interact with students. Typically, a separate group is set up for each subject. Lecturers post notices of general interest as well as assignments, and students are expected to check the newsgroup regularly. One-one interaction can still take place via email. This can be particularly effective for off-campus students. Deakin University routinely uses this combination of newsgroup and email for off-campus computing students and those studying through Deakin Australia.
Learners and teachers can also interact within MUDs by communicating within shared virtual rooms or leaving messages.
Content delivery
A number of Universities are using the Internet to deliver content, or to support conventional content delivery. At the simplest level, students can have material delivered via email. Alternatively, they can retrieve it themselves from an ftp site or gopher server.
For a more sophisticated approach, the Computer Science department at Brigham Young University in the US has created its own homepage on the World Wide Web. This homepage contains links to information about courses, staff, resources, a guided tour of the building and the department magazine. A number of the courses have their own WWW pages. For instance, the CS330 Concepts of Programming Languages homepage points to reference material, summaries of the lectures, assignments and sample solutions, classlists, and more. It is an excellent example of how to use WWW to support on-campus delivery.

Figure 2 shows the MacWeb client accessing the CS330 homepage.
As an example of how to use the Internet to deliver content (and interact with students), the Usenet University-Global Network Academy initiative aims to provide a complete university online. . Their main site for delivery of information is the Diversity University MOO which has a homepage here. This 'virtual' university has staff offices, student facilities, teaching spaces, a campus map, educational exhibits, and links to other Internet reference material. Students talk to staff, meet with each other, tap resources, submit work and access content all inside the MOO.
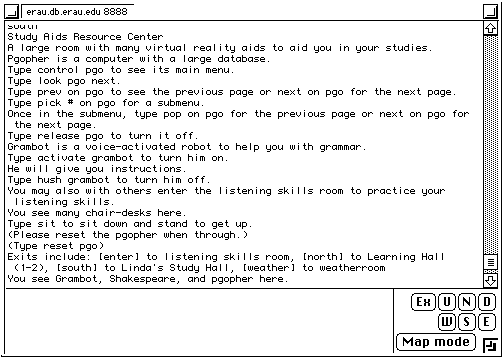
Figure 3 shows a typical location inside Diversity University. At the time of writing Introduction To Object-Oriented Programming Using C++ is underway, coordinated by an academic from Germany and with students from around the world. Proposed and registered courses include Microbial Ecology and Environmental Microbiology, Art and Technology, Introduction to Screenwriting, and Renaissance Culture. UU-GNA also provides courses via WWW from a site in Taiwan. The ultimate aim is to have course material sourced from around the world.
Research
The Internet can provide support for research by enhancing the process of gathering information and publishing its results. The formation of invisible colleges is of course of enormous benefit in the research process.
Information gathering
In discussing use of the Internet to gather information it should be stressed at the start that the Internet is only a part of a broader information ecology (Rutkowski [1994]). Agre [1994a] contains a good discussion of a whole range of strategies for getting help with research, including use of network newsgroups. Researchers still need to use their library for a variety of reasons: a lot of information is still only available in print form, proprietary databases may only be accessible on CD-ROM, and librarians will always excel at organising and locating information. In looking for information on the Internet, the University of Michigan Clearinghouse for Internet Subject-specific Resource Guides is an excellent place to start. WAIS databases now exist for a wide range of topics, and the directory of sources can be used to locate the most appropriate source to search. Those without a WAIS client can telnet to quake.think.com and login as wais. The Gopher Jewels service provides lists of Gopher services grouped by subject area. An increasing number of WWW indexes are being brought on line. Excellent places to start are:
An ever-increasing amount of material is being produced in machine-readable form and is finding its way onto the Internet, although coverage in some areas is still patchy.
Publishing
Research has to be published to be maximally useful to the scholarly community, and needs to be published to be validated by that community. The Internet can be used in a variety of ways to facilitate this process.
At the simplest level, the Internet can and is being used to facilitate the production of print publications. As more and more academics become networked, communication between writer, editor and referees via email becomes feasible. This means much faster turnaround, and simplifies the tasks of all concerned. It is possible for an editor to request a change from the writer and receive it the same day.
Email can also be used for the submission of manuscripts (a very archaic word in this context!). Submissions may be in plain text, or native document format, depending on what the publisher can cope with. No re-keying of text is required, the galley stage can often be omitted, there are fewer places where mistakes can be introduced, and the author retains better control over her/his intellectual property.
Moving away from paper, we come to electronic publishing. This can have two meanings - making information of all sorts available electronically, and the production of electronic books or journals. Eric Wainwright from the National Library of Australia has argued that all government information now needs to be created on the assumption that it is to be accessible globally (Wainwright [1993]), and this is clearly a trend in the United States. In the academic arena, many universities are implementing Campus-Wide Information Systems (Foley and Lucia [1993]) to facilitate staff and student access to a wide range of university-generated information.
Electronic journals and books are a growing field in their own right. For more information, the reader is referred to Bailey [1992, 1994], two excellent bibliographies dealing with network-based electronic publishing. These provide coverage of a whole range of issues including related topics, such as digital libraries, intellectual property rights, the NII and the NREN, and network software tools. A good place to start looking for ejournals is here. The main decisions for those wishing to undertake such publishing are the format of the information and the means of delivery.
Until recently, most electronic publishing was usually text only. This is because plain 7-bit ASCII text is the lowest common denominator on the Internet - any machine can read it. Production of such text requires careful formatting, although some word-processors provide a Text With Layout output option or equivalent which can help. Some semi-standard word-processor formats can also be used. Microsoft's Rich Text Format (rtf) can be interpreted by a number of other packages and preserves much of the formatting.
The recent surge in interest in, and use of, the World-Wide Web has meant that a number of individuals and organisations are creating documents designed to be placed on Web servers or accessed through Web clients. Such documents are written in the device-independent Hypertext Markup Language (HTML). HTML documents can have formatted text, multiple levels of headings, more than one font, internal hyper-links, the option of embedded graphics, and links out to other information resources on the Internet. The Complexity International journal is a good example.

Figure 4 shows the homepage for this journal.
Delivery of electronic material can occur in a number of ways. Listservers can be used to mail out the text of documents or a list of documents that can be retrieved. The Public Access- Computer Systems Review employs this technique. Subscribers to the lists PACS-L and PACS-R receive the table of contents as an email message, together with the commands needed to retrieve each article. They can select just the articles they wish to read. Gopher and WWW can both be used to organise access to stored documents. Both allow the user to read articles online, or save them to disk for later use. Ftp can also be used as a delivery vehicle; documents can be stored on a publicly accessible machine and the instructions on how to retrieve them mailed out or posted to a newsgroup. All of these techniques can be observed in the list of references for this paper. Databases containing text documents can be also searched and the documents retrieved using WAIS.
One of the strengths of the Internet is that the flow of information is quite democratic; anyone can publish to the world. They simply need to place their information somewhere accessible (Gopher site, WWW server, ftp site) and advertise. This egalitarian publishing environment brings with it some problems. In particularly there is a need for controls on quality. A number of the electronic journals are solving this by the traditional means of sending material to referees before publication. With the use of email this can be quite a quick process and still allow timely publication. Some ejournals have both a refereed and a non-refereed section. The Electronic Journal on Virtual Culture (EJVC) is a good example. Other ejournals rely on their editors to act as filters of poor-quality material, and the reputation of their editors in the Internet community to guide the reader's choice of that ejournal.
Electronic publishing still has problems with complex formatting, particularly of complex equations, although the WWW community is actively debating extensions to HTML to resolve this. It still seems likely that 7-bit ASCII as a Lowest Common Denominator will be around for some time to come.
Conclusion
This article has tried to explore some of the ways in which the Internet can change and is changing the way in which academics operate. Access to network infrastructure is increasingly being seen as essential for university academics, in the same way as a good library on-campus and a telephone on one's desk. The Internet and its rapid growth and development are enabling completely new ways to organise and access information. Old paradigms for working with information are breaking down (Treloar, [1994]), and scholars as quintessential information workers need to change and adapt. Some of the initiatives described in this paper are simply new ways of doing old things better. Others are new things completely. The tools and technologies that the Internet provides enable scholars to communicate or disseminate information in ways which conquer the barriers of time and space. All scholars can now 'work globally, live locally'. The implications of this for the nature of universities and academic endeavour will no doubt be profound.
References
Agre, P. [1994a], "The art of getting help", The Network Observer, Vol. 1, No. 2, February. To retrieve this file, send an email message to rre-request@weber.ucsd.edu with the text archive send tno-february-1994 in the subject line.
Agre, P. [1994b] Networking on the Network., version of May 29. To retrieve this file, send an email message to rre-request@weber.ucsd.edu with the text archive send network in the subject line.
Bailey, Charles W., Jr. [1992] "Electronic Publishing on Networks: A Selective Bibliography of Recent Works." The Public-Access Computer Systems Review, vol. 3, no. 2, pp. 13-20. To retrieve this article, send an e-mail message that says GET BAILEY PRV3N2 F=MAIL to listserv@uhupvm1.uh.edu.
Bailey, Charles W., Jr. [1994] "Electronic Publishing on Networks: Part II of a Selective Bibliography." The Public-Access Computer Systems Review, vol. 5, no. 2 , pp. 5-14. To retrieve this file, send the following e-mail message to listserv@uhupvm1.uh.edu: GET BAILEY PRV5N2 F=MAIL. (The file is also available from the University of Houston Libraries' Gopher server: info.lib.uh.edu, port 70.)
Berners-Lee, Tim et al. [1992], "World-Wide Web: The Information Universe" Electronic Networking: Research, Applications and Policy , vol. 2, no. 1, pp. 52-58.
Bowman, C. M., Danzig, P. B., and Schwartz, M. F. [1993], "Research Problems for Scalable Internet Resource Discovery", Proceedings of INET '93.
Caplan, Priscilla [1993], "Cataloging Internet Resources", The Public-Access Computer Systems Review Vol. 4, no. 2, pp. 61-66.
CCITT/ISO [1988], The Directory, Part 1: Overview of Concepts, Models and Services. CCITT Draft Recommendation X.500/ISO DIS 9594-1, CCITT/ISO, Gloucester, England.
December, John [1994a], Internet-Tools. Available in Text, Compressed Postscript, and HTML.
December, John [1994b], Internet-CMC. Available in Text, Compressed Postscript, and HTML.
Deutsch, Peter [1992], "Resource Discovery in an Internet Environment-- The Archie Approach." Electronic Networking: Research, Applications and Policy, vol. 2, no. 1, pp. 45-51.
EARN Association [1993], Guide to Network Resource Tools, Version 2.0. This document is available in electronic format from LISTSERV@EARNCC.BITNET. Send the command: GET filename where the filename is either NETTOOLS PS (Postscript) or NETTOOLS MEMO (plain text).
Foley, T. and Lucia, J., [1993], "Campus-wide Information Systems: Information Navigation Facilities for the '90s", Proceedings of VALA '93, Melbourne, pp. 144 - 152.
Foster, Jill, Brett, George, and Deutsch, Peter [1993], A Status Report on Networked Information Retrieval: Tools and Groups, Joint IETF/RARE/CNI Networked Information Retrieval - Working Group (NIR-WG)
Hardy, D. R. and Schwartz, M. F. [1993], "Essence: A Resource Discovery System Based on Semantic File Indexing", Proceedings Winter USENIX Conference, San Diego, pp. 361 - 373.
Harrenstein, K., Stahl, M., and Feinler, E. [1985], NICName/WHOIS. RFC 954. SRI International.
Harrison, Teresa M., Timothy Stephen, and James Winter. [1991] "Online Journals: Disciplinary Designs for Electronic Scholarship." The Public-Access Computer Systems Review, vol. 2, no. 1, pp. 25-38. To retrieve this article, send an e-mail message that says GET HARRISON PRV2N1 F=MAIL to listserv@uhupvm1.uh.edu.
Kahle, Brewster et al. [1992], "Wide Area Information Servers: An Executive Information System for Unstructured Files." Electronic Networking: Research, Applications and Policy , vol. 2, no. 1, pp. 59-68.
Lynch, C. A., and Preston, C. M. [1992], "Describing and Classifying Networked Information Resources", Electronic Networking Research, Applications and Policy Vol. 2, No. 1, Spring, pp. 13-23.
Neuman, B. Clifford [1992], "Prospero: A Tool for Organizing Internet Resources", Electronic Networking: Research, Applications and Policy, vol. 2, no. 1, Spring.
Neuman, B. Clifford, and Augart, Steven Seger [1993], "Prospero: A Base for Building Information Infrastructure", Proceedings of INET '93.
Obraczka, K., Danzig, P. B., and Li, S. [1993], "Internet Resource Discovery Services", IEEE Computer, September, pp. 8 - 22.
Okerson, Ann. [1991] "The Electronic Journal: What, Whence, and When?" The Public-Access Computer Systems Review, vol. 2, no. 1, pp. 5-24. To retrieve this article, send an e-mail message that says GET OKERSON PRV2N1 F=MAIL to listserv@uhupvm1.uh.edu.
Rutkowski, T. [1994], State of the Internet (Powerpoint Presentation). Internet Society, Reston, VA, April.
Savetz, Kevin [1993], Internet Services Frequently Asked Questions and Answers.
Schwartz, M. F. and Tsirigotis, P. G. [1991], "Experience with a Semantically Cognizant Internet White Pages Directory Tool" J. Internetworking: Research and Experience, Vol. 2, No. 1, March, pp. 23 - 50.
Schwartz, M. F., Emtage, A., Kahle, B. and Neuman, B. C. [1992], "A Comparison of Internet Resource Discovery Approaches", Computing Systems, vol. 5, no. 4, Fall, pp. 461 - 493.
Scott, Peter. [1992], "Using HYTELNET to Access Internet Resources." The Public-Access Computer Systems Review, vol. 3, no. 4, pp. 15-21. To retrieve this file, send the following e-mail message to LISTSERV@UHUPVM1.UH.EDU : GET SCOTT PRV3N4 F=MAIL.
Stain, Richard M. [1991], "Browsing through Terabytes", Byte, May 1991, pp. 157 - 164.
Stanton, Deidre E. [1992]. Tools For Finding Information on the Internet: HYTELNET, WAIS and Gopher. Murdoch University Library, Murdoch, WA. Available in Text, Postscript, or WordPerfect formats.
Treloar, A. [1993], "Towards a user-centred categorisation of Internet access tools", Proceedings of Networkshop '93, Melbourne.
Treloar, A. [1994], " The Internet as an Information Management Technology: New Tools, New Paradigms and New Problems", paper accepted for the 47th Conference of the International Federation for Information and Documentation (FID), Omiya, Japan, October 2 - 9, 1994.
Wainwright, E. [1993], "Networked Library Applications: Towards a Coherent Strategy", Proceedings of Networkshop '93, Melbourne.
Warnock, J. [1992], "The new age of documents", Byte, June 1992, pp. 257 - 260.
Wiggins, Rich. [1993], "The University of Minnesota's Internet Gopher System: A Tool for Accessing Network-Based Electronic Information." The Public-Access Computer Systems Review vol. 4, no. 2, pp. 4-60. To retrieve this file, send the following e-mail messages to LISTSERV@UHUPVM1.UH.EDU: GET WIGGINS1 PRV4N2 F=MAIL and GET WIGGINS2 PRV4N2 F=MAIL.
Yanoff, Scott [1993], Special Internet Connections List, posted periodically to alt.internet.services. Finger yanoff@csd4.csd.uwm.edu for more information.
Zakon, R. H. [1994], Hobbes' Internet Timeline v 1.2, April 29. To receive the latest version, send e-mail to timeline@hobbes.mitre.org. You will receive an automated reply with the Timeline.
ó